


医療レセプトデータから「インサイト」を生み出すデータサイエンスパイプライン
目次
著者:佐藤能臣a,b,坂本唯史a,市原泰介b
所属:a(株)データフォーシーズ AI Lab
b日本システム技術(株)ライフイノベーション LAB
概要:新型コロナウイルス感染症(COVID-19)のパンデミックにより、世界の医療AI市場の急速な成長が見込まれています。日本も、その成長の波に乗り遅れないためにも、医療業界の現状の課題や、データサイエンスに求められているニーズを把握する必要があります。本稿では、COVID-19感染拡大推移分析に関するデータサイエンスパイプライン(図1を参照)の基礎から、どのようなデータサイエンス技術を用いれば、大規模医療レセプトデータベースから、本質的に価値ある分析結果を出していけるのかを模索します。その結果、感染専門医の報告と同様に、「第1波と第2波では、年代で感染拡大や重症化の傾向が異なっていた可能性のある」知見を見出します。
はじめに
世界の医療AI市場の成長予測
COVID-19感染拡大で、世界の製薬及びバイオテック企業が医療AIの活用を模索し始めたことを背景に、去年の2020年段階で49億ドルと試算された医療AI市場は、2026年までに452億ドル規模の急成長が見込まれるようになっています1,2。また、Reportocean.comの新しい報告でも、2019年に4,836.87百万ドルと試算されたヘルスケア市場のAIが2027年までに99,491.58百万ドルに達し、年平均成長率も42.8%を記録することが予想されています3。
日本医療の課題
日本も、今後の世界の医療AI市場の成長の波に乗るためにも、まず初めに、国内の医療業界の課題を俯瞰します。
DataRobotのデータサイエンティストの伊地知氏のブログ記事4でも言及されていますが、日本の医療では、次の3つが課題です:「高齢化と人口減少」「社会保障費の増加」「疾病構造の変化」。特に、3番目の「疾病構造の変化」については、厚生労働省の「H27年 人口動態統計」5で示された「主要死因別の死亡率の推移」から、昭和20年代以降、結核による死亡が大きく減少し、日本の死因構造の中心は、感染症から生活習慣病に大きく変わっていることがわかります。そして、今回のCOVID-19の世界規模の大流行により、変異株も含めたCOVID-19感染による直接的な死因とCOVID-19の感染症の併発による生活習慣病の重症化の間接的な死因の2つを考慮に入れた疾病構造を想定し社会活動を営む必要性が出てきたかもしれません。
特に、糖尿病、高血圧、がん、心疾患、脳血管疾患などの生活習慣病は、死亡原因では6割、医療費では3割を占めており、国民の健康に対する大きな脅威となっています6,7。生活習慣病の重症化予防等の、膨大な医療費がかかる重篤疾患にかかる患者数の減少による医療費の削減をどれだけ実行できるかが重要になってくると考えられます。医療費削減の推進のために、病院等の医療機関は、レセプトデータを積極的に活用したい意向があります。それは、レセプトデータを管理し、事業展開を考えている企業も同様です。
日本のレセプトデータの利活用の現状
レセプトビッグデータを活用し分析サービスビジネスを展開するJMDC社では、生活習慣病のうちの糖尿病を罹患している患者の慢性腎臓病を重症度別に分析を行なっているようです8。最近の、日本メディカルAI学会の学術集会でも、レセプトデータから時系列データを抽出し機械学習を適用した予測分析事例など、数多くの事例が報告されています9。また、日本システム技術(JAST)社及びデータフォーシーズ(D4c)社は、共同開発した「COVID-19感染リスク分析Dashboard」を公開しましたが10、このDashboardには、JAST社が保有するレセプトデータベースから抽出されたCOVID-19感染関連のレセプトデータを用いたベイズ統計モデルに基づく感染リスクシミュレーション機能が搭載されています。このDashboardは、コロナ感染リスクポータルサイト「コロミル」11として機能拡張し先月末公開されました。
このように、医療業界も、ビッグデータ分析としてではなく、機械学習・AIとしてデータサイエンスに注目し始めています。データサイエンス技術の進化により、医療ビッグデータの弱点に適応的に対処しながらも、本質な洞察が得られるようになったからであり、「レセプト情報・特定健診等情報データベース(NDB)」以上に、医療ビッグデータを保有する企業内の環境が整備され始めてきたからです。
今後、機械学習・AIを駆使した医療ビッグデータ分析のニーズや機会が益々増えてくるでしょう。そのような医療従事者や研究者、企業からニーズに対し誠実に対応していくためにも、レセプトデータの取り扱いをデータサイエンスの視点からもう一度再確認します。特に、レセプトデータ等の医療ビッグデータ解析のデータサイエンスパイプラインを詳細に分析することで、新たな価値と可能性を見出していきます。
データサイエンスパイプライン

図 1 データサイエンスパイプラインとは、加工前のデータを用い、データサイエンス技術を駆使し説得力のあるデータを創造する作業工程です。
「データサイエンスパイプライン」という言葉は、日本では、あまり聞き慣れませんが、海外のデータサイエンスビジネスにおいて、頻繁に用いられる用語で、加工前のデータからビジネス上の課題に対する実用的な解決案の提案へと変換する、一連のエンド・トゥ・エンドのデータ加工処理工程を指します12,13。例えば、ソースから宛先へのデータフローを自動化し、最終的にはビジネス上の意思決定を行うための「インサイト」や「データプロダクト」を示します(本稿では、「データプロダクト」の詳細は割愛しますが、例えば、リッキー・ヘネシー著「優れた『データプロダクト』を設計するための9の原則」14をご参照下さい)。
本稿では、JAST社が保有する医療レセプトデータベース15(個人情報保護法に遵守し、被保険者の2次利用許諾を得た上で個人が特定できない匿名加工済みのデータのみを利用した)を利活用し、データサイエンスパイプラインの概要の「データキャプチャ」「データアナリシス」「データストーリーテリング」から、本質的で、価値のある分析結果を見出していきます。
データキャプチャ
「データキャプチャ」とは、データ収集やデータ加工(例えば、匿名加工のための集計処理も含みます)、データ整形を通して、データに対して疑問を提起し続ける作業、データモデリングの意味を含みます。この作業により、データがどのような関係性を持ち、どのように構造化されているのかを理解することができるようになります。
例えば、匿名加工・集計した医療レセプトデータから、次の疑問に対する回答を導くことができるかもしれません:
- レセプトデータ上のCOVID-19陽性、または、陰性の定義は何ですか?
- そのCOVID-19陽陰性の定義は、PCR検査と関係がありますか?
- 感染リスクは、どのように定義されるのでしょうか?
- COVID-19感染と生活習慣病の重症化との間に因果性はあるでしょうか?
- COVID-19に感染してしまった場合の医療費は、どのくらいかかるのでしょうか?
得られたデータに対して疑問を持つことは、とても大切です。その理由は、疑問を持てば持つほど、より深く多くの「インサイト」が得られるからです。そして、その「インサイト」が、ビジネスを変える可能性を秘めた「データプロダクト」や「データストーリーテリング」のアイディアを生み出します13。
例えば、JAST及びD4cが共同開発したDashboard10の「リスク分析:バブルチャート」で使われた集計データは、医療レセプトデータベース15から、「レセプトデータ上のCOVID-19陽性、または、陰性の定義は何ですか?」「感染リスクは、どのように定義されるのでしょうか?」「COVID-19に感染してしまったら、医療費はどのくらいかかるのでしょうか?」の疑問に基づいて、属性別に2020年1月〜8月の受診者数、コロナ陽性者数、コロナ陽性者の負担した医療費総額にデータ整形されたものです。
データアナリシス
データアナリシスとは、一般的に、「データキャプチャ」で得られたデータモデルを用い、大学程度の統計学で分析を行うことです16。本稿では、前述の疑問「感染リスクは、どのように定義されるのでしょうか?」から、属性毎に2020年1月〜8月の全体人数、コロナ陽性者数から感染率を算出します。また、コロナ陽性者数とコロナ陽性者が負担した医療費総額から一人当たり医療費を算出します。
データストーリーテリング
データストーリーテリングとは、「データから得られた『インサイト』を、ユーザーに分かりやすく伝え、期待するアクションに繋げる手法」です17。「データアナリシス」までで、アクセシブルかつエンゲージしやすくデータ整形できたおかげで、バブルチャートを用い、可視化することで、属性別に、コロナ陽性者が負担する一人当たり医療費額と感染率の傾向を把握できるようになりました。バブルチャートとは、図2で示されるように、散布図を構成する2つのデータ(本稿では、一人当たり医療費及びコロナ感染率)に加え、その2つのデータと関係するデータ(感染リスク(risk):感染する可能性を定量化したもの)を追加し、円の大きさとして表す可視化手法です。
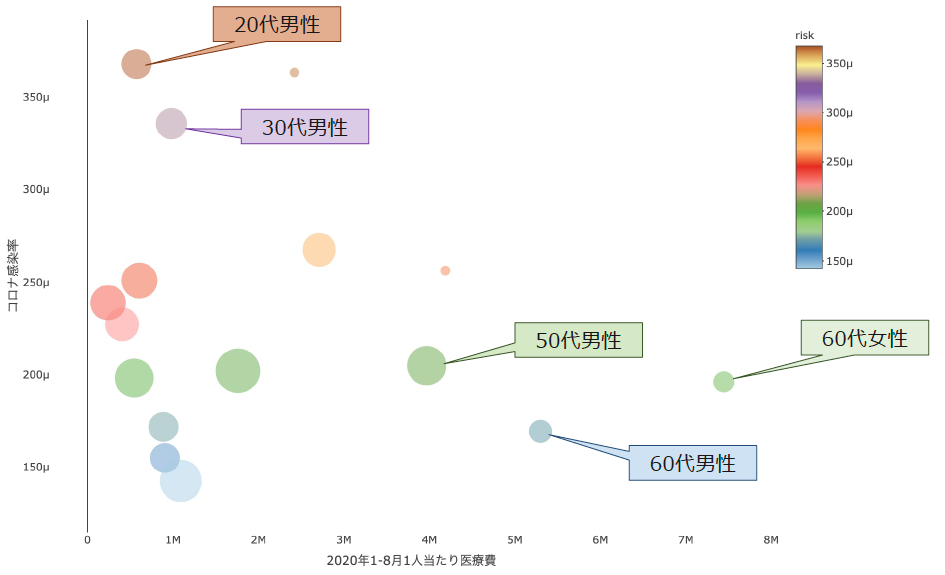
図 2 性年代別のrisk(感染リスク)のバブルチャートによる可視10
この結果から、「50代、60代の方は予防や行動制限により感染率や感染リスクは低く抑えられているものの、感染してしまう基礎疾患や持病などの重症化の影響で負担する医療費の高額化につながっている可能性がある」あるいは、「20代、30代は、他の年代に比べ、テレワーク勤務が十分に浸透していない時期での職場への出向など外出で感染率や感染リスクは比較的高いが、重症化に起因する基礎疾患がないため負担する医療費は低額傾向にある」という「インサイト」が得られます。
結論
上記の「インサイト」は、感染症専門医の忽那賢志の見解18も絡め、信頼性を持たせることで説得力が増すようになります。忽那賢志は、「第1波での50代及び60代の感染拡大。第2波での20代及び30代の感染拡大」傾向を報告していましたが、この傾向報告を踏まえると、上記の得られた「インサイト」は、
- 第1波:基礎疾患や持病を持つ60代で感染が拡大し重症化した
- 第2波:20代及び30代で感染が拡大したが、基礎疾患や持病を持たないため重症化が抑えられていた
可能性を示唆します。この示唆について、更に厳密な妥当性を示すには、「データキャプチャ」「データアナリシス」で、属性別に加え、月別の感染率や一人当たり医療費を算出するロジックを組み直す必要があると考えられます。
謝辞
本記事の内容の一部は、日本システム技術(株)ライフイノベーションラボとの共同研究開発契約「医療レセプトデータを利用したAIサービス事業化」のもとで行われた。議論や意見を頂いた(公財)佐々木研究所附属杏雲堂病院の相馬正義院長に心から感謝します。
参考文献
Tokyo analytica:「2026年までに医療AI市場は452億ドル規模へ」The Medical AI Times(https://aitimes.media/2020/06/24/5387/?9642,2020年6月24日).
“Artificial Intelligence in Healthcare Market with Covid-19 Impact Analysis by Offering (Hardware, Software, Services), Technology (Machine Learning, NLP, Context-Aware Computing, Computer Vision), End-Use Application, End User and Region – Global Forecast to 2026.” (https://www.researchandmarkets.com/reports/5116503/artificial-intelligence-in-healthcare-market-with?utm_source=dynamic&utm_medium=BW&utm_code=82zkmp&utm_campaign=1404799+-+%2445.2+Billion+Worldwide+Artificial+Intelligence+in+Healthcare+Industry+to+2026+-+Featuring+Lunit%2c+Magnea+%26+Maxq+AI+Among+Others&utm_exec=jamu273bwd, Marketsandmarkets, 2020 June 9th).
「ヘルスケア市場のAIは、2027年まで42.8%のCAGRで目覚ましい成長が見込まれています」PRTIMES (https://prtimes.jp/main/html/rd/p/000000414.000067400.html,2021年1月5日).
伊地知晋平「医療業界(病院や医療系研究機関)でのAI/機械学習の利用」DataRobot (https://www.datarobot.com/jp/blog/machine_learning_usage_in_medical_field/, 2020年3月12日).
厚生労働省「平成27年 人口動態統計月報年計(概数)の概況」(https://www.mhlw.go.jp/toukei/saikin/hw/jinkou/geppo/nengai15/index.html,2016年5月23日報道発表).
厚生労働省「平成19年版 厚生労働白書 医療構造改革の目指すもの」(https://www.mhlw.go.jp/wp/hakusyo/kousei/07/,2007年).
厚生労働省「平成21年 慢性疾患対策の更なる充実に向けた検討会 検討概要」(https://www.mhlw.go.jp/stf/shingi/other-kenkou_128616.html,2009年8月26日).
JMDCホームページhttps://www.jmdc.co.jp/
日本メディカルAI学会学術集会https://jmai2021.org/
(開発)佐藤能臣,坂本唯史,(データ提供)市原泰介,(監修)相馬正義「JAST-D4c 新型コロナウイルス感染症(COVID-19)感染リスク分析Dashboard」日本システム技術株式会社 イノベーション Lab & データフォーシーズ AI Lab (https://the-jast-d4c-risk.shinyapps.io/main/,2021年4月28日公開).
(開発)佐藤能臣,坂本唯史,(データ提供)市原泰介,(監修)相馬正義「コロナ感染リスクポータル コロミル」日本システム技術株式会社 イノベーション Lab & データフォーシーズ AI Lab(https://various-liquid-2184.glideapp.io/,2021年7月27日公開).
Snowflake workload guides「DATA SCIENCE PIPELINE in DATA SCIENCE」https://www.snowflake.com/guides/data-science
Vinit Saini 「Overview of the Data Science Pipeline」DZone (https://dzone.com/articles/overview-of-the-data-science-pipeline, 2018, Nov. 06)
リッキー・ヘネシー「優れた『データプロダクト』を設計するための9の原則」AXIS Webマガジン(https://www.axismag.jp/posts/2018/04/90642.html,2018年4月4日),電通報(https://dentsu-ho.com/articles/5958,2018年4月10日).
日本システム技術株式会社「保険者向けトータルサービス『JMICS』」(https://www.jast.jp/service/medical/).
J. P. Mueller, Luca Massaron: “Python for Data Science for dummies, 2nd Edition.” (Jonh Wiley & Sons, Inc., New York, United States, 2019).
Unyoo.jp編集部「【コラム】データストーリーテリングなdashboardを構築するポイント 〜ビジュアライズ編〜:Domopalooza 2019」(https://unyoo.jp/2019/06/datastorytelling-visualize/,2019年6月11日).
忽那賢志「新型コロナ第3波はすでに医療機関を逼迫させつつある」(https://news.yahoo.co.jp/byline/kutsunasatoshi/20201114-00207816/,2020年11月14日).


